
Tesla hat gestern den Schalter seines neuen KI-Clusters mit 10.000 Nvidia H100 Compute GPUs umgelegt. Musk plant demnächst mehrere Milliarden in KI zu investieren. Tesla verwendet Grafikprozessoren (GPUs), um seine neuronalen Netze zu trainieren, die zur Lösung von KI-basierten Problemen eingesetzt werden.
Beim Training der KI von Tesla werden riesige Mengen an Videomaterial verwendet, um dem System beizubringen, wie es ein Fahrzeug autonom und sicher steuern kann. NVIDIA, ein führender Hersteller von Grafikprozessoren, hat kürzlich einen neuen Chip, den H100, auf den Markt gebracht, der eine deutlich höhere Leistung als sein Vorgänger, der A100, bietet. Allerdings ist der H100 nicht billig. NVIDIAs neuester, auf die Ausbildung ausgerichteter Grafikprozessor kostet etwa 30.000 Dollar, und Tesla braucht mehr als nur eine Handvoll davon.
Tesla startet Supercomputer
Gestern hat Tesla seinen mit Spannung erwarteten Supercomputer in Betrieb genommen. Die Maschine wird für verschiedene Anwendungen im Bereich der künstlichen Intelligenz (KI) eingesetzt werden, aber der Cluster ist so leistungsfähig, dass er auch für anspruchsvolle High-Performance-Computing (HPC)-Workloads verwendet werden könnte. Tatsächlich wird der auf Nvidia H100 basierende Supercomputer einer der leistungsstärksten Rechner der Welt sein.

Der neue Tesla-Cluster setzt 10.000 Nvidia H100 Compute GPUs ein, die eine Spitzenleistung von 340 FP64 PFLOPS für technische Berechnungen und 39,58 INT8 ExaFLOPS für KI-Anwendungen bieten werden. Die 340 FP64 PFLOPS von Tesla sind sogar höher als die 304 FP64 PFLOPS von Leonardo, dem weltweit viertstärksten Supercomputer.
Mit seinem neuen Supercomputer steigert Tesla seine Rechenkapazitäten erheblich, um seine FSD-(Full Self-Driving) Technologie schneller als je zuvor zu trainieren. Das könnte Tesla nicht nur wettbewerbsfähiger als andere Autohersteller machen, sondern das Unternehmen auch zum Besitzer eines der schnellsten Supercomputer der Welt machen.
“Dank dem Videotraining in der realen Welt verfügen wir möglicherweise über die größten Trainingsdatensätze der Welt und eine Hot-Tier-Cache-Kapazität von mehr als 200 PB – um Größenordnungen mehr als LLMs”, erklärte Tim Zaman, AI Infra & AI Platform Engineering Manager bei Tesla.
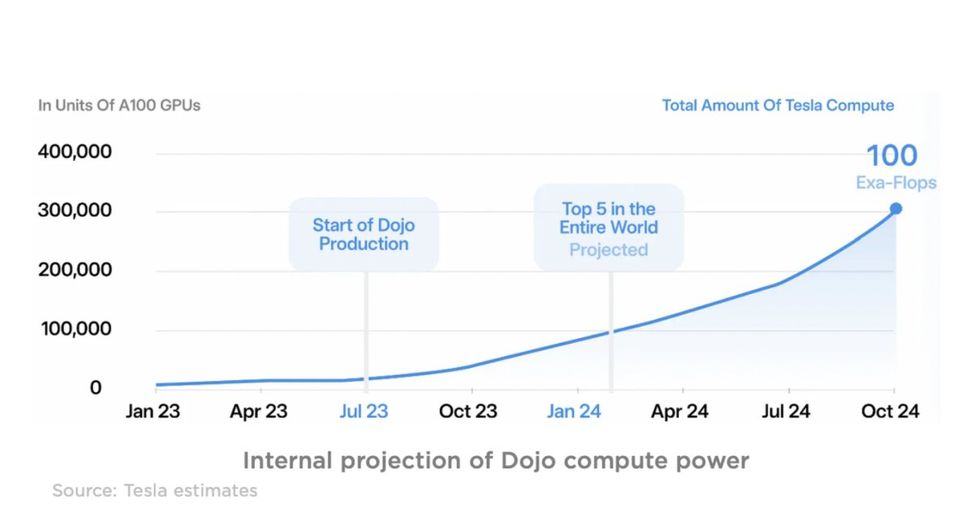
Während der neue H100-basierte Cluster die Trainingsgeschwindigkeit von Tesla drastisch verbessern wird, hat Nvidia Probleme, die Nachfrage nach diesen GPUs zu befriedigen. Aus diesem Grund investiert Tesla über 1 Milliarde Dollar in die Entwicklung seines eigenen Supercomputers Dojo, der auf speziell entwickelten, hoch optimierten System-on-Chips basiert.
Dojo wird nicht nur das FSD-Training beschleunigen, sondern auch die Datenverarbeitung für die gesamte Fahrzeugflotte von Tesla übernehmen. Gleichzeitig mit Dojo bringt Tesla seinen Nvidia H100-GPU-Cluster online, wodurch das Unternehmen über eine in der Automobilbranche einzigartige Rechenleistung verfügt.
Musk plant Investitionen in KI
Elon Musk hat vor kurzem verraten, dass Tesla plant, dieses Jahr über 2 Milliarden Dollar für KI-Training und weitere 2 Milliarden Dollar im nächsten Jahr speziell für das Computing für FSD-Training auszugeben. Das unterstreicht das Engagement von Tesla bei der Überwindung von Rechenengpässen und dürfte dem Unternehmen erhebliche Vorteile gegenüber seinen Konkurrenten verschaffen.
Bildnachweis: @SawyerMerritt | Twitter
Ähnliche Beiträge





